Les sondages de l’élection présidentielle se copient-ils entre eux ?
Les sondages de l’élection présidentielle se copient-ils entre eux ?
Par Maxime Ferrer, Laura Motet, Gary Dagorn
A quelques jours du premier tour, plusieurs statisticiens accusent les sondeurs français de s’inspirer des résultats de leurs concurrents. Un phénomène appelé le « herding ». Qu’en est-il ?
Brexit, Trump, la surprise Le Pen en 2002 : trois chocs pour l’opinion publique, trois occasions où les résultats ont déjoué les pronostics et nourri la défiance à l’égard des sondeurs. A quelques jours du premier tour de l’élection présidentielle, les sondeurs voient une nouvelle fois leurs estimations remises en cause. La critique arrive tout droit des Etats-Unis avec ce qu’ils appellent le « herding ».
Le herding (que l’on peut traduire par « suivisme » en français) désigne un phénomène que l’on peut observer lors d’une campagne électorale lorsque les sondeurs publient des résultats volontairement proches des autres sondages publiés par crainte d’apparaître dans l’erreur et d’être discrédités une fois les résultats connus.
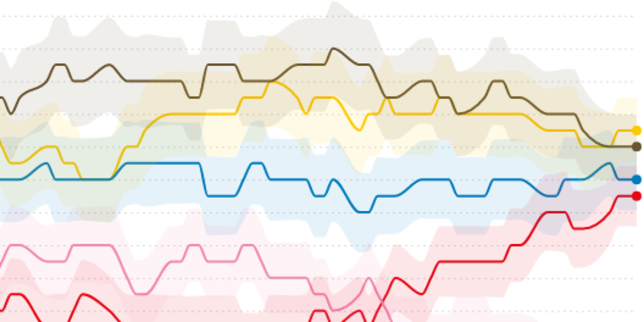
Et c’est très exactement ce qui se passerait avec les sondages français selon le journaliste-statisticien américain Nate Silver, qui avait correctement prédit les résultats de la présidentielle américaine en 2008 et 2012. Ce dernier s’inquiète ouvertement de la convergence globale des sondages français.
Une analyse reprise dans la foulée, dans un article sur la partie blog de The Economist qui interroge : « Les sondeurs français trichent-ils ? » Les arguments de Nate Silver ont été également repris par un étudiant-chercheur assistant au MIT Media Lab, Léopold Mebazaa, qui tente de démontrer que la convergence des sondages est trop importante pour ne pas jeter un doute sur les méthodes des sondeurs.
Des méthodes différentes en France et aux Etats-Unis
Pour comprendre le débat qui est posé, il faut s’intéresser aux techniques de sondages pratiquées en France et aux Etats-Unis. Côté américain, c’est la méthode dite « probabiliste » qui est la plus répandue. Les sondeurs tirent au hasard un échantillon au sein de la population, puis en étudient les propriétés (intention de vote, opinion sur un sujet, etc.). Certains sondeurs opèrent ensuite des redressements sur les résultats pour essayer de coller au maximum à la structure de la population américaine.
Côté français, tous les sondeurs utilisent la méthode dite « non-probabiliste », à savoir la méthode des quotas : on crée un échantillon selon des variables (âge, sexe, profession, lieu d’habitation, c’est ce qu’on appelle des variables sociodémographiques) afin que celui-ci soit représentatif de la population étudiée (la population française par exemple). Si les personnes sont bien choisies au hasard, leurs caractéristiques ne le sont pas.
Dans le cas précis des estimations des intentions de vote, deux autres variables agissent directement sur les résultats : le vote de la personne interrogée à la présidentielle de 2012 et aux dernières élections régionales. Ces variables servent à redresser les résultats obtenus pour que la structure de l’échantillon corresponde, en plus des caractéristiques sociodémographiques, à celle des résultats de ces deux élections.
La méthode de Nate Silver appliquée au cas français
Calquée sur la méthode de Nate Silver, la démonstration de Léopold Mebazaa est séduisante, mais la conclusion qu’elle amène et qu’il résume dans un titre péremptoire – « Oui les sondages présidentiels sont caviardés » – s’avère moins subtile.
A partir d’un jeu de données rassemblant les sondages français sur les intentions de vote depuis début décembre 2016, l’étudiant-chercheur retourne les armes des sondeurs contre eux. Son postulat est en effet que les sondages, comme les intentions de vote d’une élection, sont distribués selon la « loi normale ». Pour faire simple, cette loi permet d’analyser un ensemble à partir d’une fraction de cet ensemble, en lui associant un niveau de confiance et des marges d’erreurs. Il existe trois paliers pour ce seuil de confiance : 68 %, 95 %, 99 %. Plus l’exigence est élevée, plus les marges d’erreurs sont importantes.
Exemple : un sondage basé sur un échantillon de mille personnes pourra prédire que des intentions de vote estimées à 20 % devraient in fine se situer entre 16,75 % et 23,25 % pour un niveau de confiance de 99 %, entre 17,5 % et 22,5 % avec 95 % de certitude ou encore entre 18,75 % et 21,25 % avec un intervalle de confiance de 68 %.
Avec la multiplication des sondages ces derniers mois, le chercheur dispose d’une « population » de sondages qu’il entend soumettre aux mêmes lois statistiques. Il propose donc de tester si les intentions de vote de chacun des quatre « gros » candidats (Marine Le Pen, Emmanuel Macron, Jean-Luc Mélenchon et François Fillon) correspondent effectivement aux principes de la loi normale.
En prenant un niveau de confiance de 68 % sa logique est simple : dans 68 % des cas les estimations des sondages devraient se situer dans l’intervalle de la marge d’erreur (plus ou moins 1,35 %), en dehors dans 32 % des cas.
Ses tests concluent qu’un nombre anormal de sondages se situe en effet à l’intérieur de cet intervalle (en moyenne plus de 80 %). Et pour enfoncer le clou, il propose de démontrer une convergence des sondages après le 25 février (date clé selon lui, car elle correspond à des « gros changements de score », au ralliement de François Bayrou à Emmanuel Macron et se situe avant la mise en examen de François Fillon). Et, là encore, ses conclusions sont accablantes :

Capture d’écran des conclusions de Léopold Mebazaa sur le site Medium | Medium.com
Une démonstration basée sur des hypothèses incertaines
Le choix de la date du 25 février peut poser question. Nous avons pris soin de réaliser les mêmes calculs que le chercheur, avec des dates allant de mi-décembre à début avril. Il en ressort que ses conclusions auraient été tout aussi valides s’il avait supposé une convergence des résultats dès la mi-janvier ou courant mars. Ensuite, en calquant l’analyse de Nate Silver sur le cas français, Léopold Mebazaa semble omettre la méthodologie française (les quotas) évoquée plus haut.
« J’ai “l’intuition” – que j’espère pouvoir tester bientôt – que le mode de sélection par quotas et le redressement (qui ne sont en fait pas aléatoires) peuvent eux-mêmes conduire à une corrélation des erreurs d’échantillonnage entre les instituts, explique Antoine Rebecq, administrateur de l’Insee dont les données servent de référence aux instituts de sondages. Cela peut donner l’impression que les sondeurs se copient, car les variables utilisées pour créer et redresser leurs échantillons sont exactement les mêmes. »
Cette observation fait planer le doute sur l’analyse du chercheur du MIT. Ses conclusions basées sur des probabilités se fondent sur un test appelé le « Khi-deux ».
Antoine Rebecq, qui met en doute le herding dans un postpublié le 20 avril sur un blog collaboratif, précise : « Le test du Khi-deux est un test qui s’intéresse à la corrélation. Il est assez logique qu’il tombe sur une corrélation du fait de la méthode des quotas. » Concrètement, ce test suppose une indépendance entre les variables. Avec la méthode des quotas, il y a donc fort à parier que les sondages français ne soient pas indépendants car tous soumis aux mêmes caractéristiques, ce qui invaliderait de facto le test réalisé.
« Cette hypothèse me paraît valable, reconnaît Léopold Mebazaa. Mais il y a deux choses que je ne m’explique pas. La première est qu’à l’issue des scrutins, les erreurs observées ont souvent été supérieures aux erreurs théoriques qui étaient présentées dans les sondages. La seconde, c’est qu’on observe systématiquement un redressement très sévère soixante jours avant l’élection. »
Des pratiques qui peuvent parfois poser question
Une source travaillant dans un institut de sondage nous a confirmé, sous couvert d’anonymat, qu’il pouvait exister des « pressions sur les personnes en charge des enquêtes d’opinion, mais sans que ce soit systématique ». Concernant le redressement des sondages sur les intentions de vote, une autre source précise que le sondeur « essaie plusieurs redressements différents, (…) puis fait un choix complètement arbitraire entre ces redressements. Il se base sur ses intuitions, sur les sondages de ses petits camarades. »
Parmi les sondeurs que nous avons contactés, François Kraus, directeur des études politique actualité au sein de l’IFOP, rejette l’idée que les sondeurs se copient entre eux.
« On ne regarde pas ce que font les autres sondeurs - nous ne sommes pas aveugles, certes, mais notre objectif est d’avoir l’estimation la plus juste. Le fait que les intentions de vote se rapprochent au fur et à mesure de la campagne signifie aussi que, progressivement, nous avons acquis plus d’expérience pour mesurer certains phénomènes nouveaux (comme le vote Macron). »
François Kraus n’hésite pas à retourner la rhétorique du chercheur du MIT contre lui : « Si on [les instituts de sondage] voit tous la même chose, c’est qu’il se passe quelque chose dans l’opinion. » Verdict dimanche soir.
Malgré la convergence des sondages, des inconnues subsistent
Au soir du premier tour, les Français ne sont pourtant pas à l’abri d’une surprise. Le 21 avril 2002, vers 19 h 30, David Pujadas annonce des « surprises ». Quelques minutes plus tard, les téléspectateurs apprennent la qualification au second tour de Jean-Marie Le Pen. « Une telle sous-estimation du vote FN est moins à craindre aujourd’hui. Avec l’usage des questionnaires auto-administrés sur Internet, le biais de désirabilité sociale est considérablement réduit », explique François Kraus. En effet, en 2002, les instituts de sondages avaient effectué leurs entretiens par téléphone ou en face-à-face. Des méthodes qui entraînent une sous-déclaration des votes dits « honteux », le sondé craignant le jugement du sondeur.
Ce problème de mesure réglé, il n’en reste pas moins que la fiabilité des sondages peut aussi être questionnée au regard de l’échantillon de population choisi. Si les sondeurs présentent volontiers leur travail comme une « photographie de l’opinion publique française à un instant T », aucun n’inclut dans son sondage les intentions de vote des inscrits dans les DOM-TOM, alors que plus de 2,8 millions des inscrits y résidaient en 2012.
Cette absence de 6,2 % du corps électoral pourrait être à l’origine de surprises au soir du premier tour. Elle s’explique en partie par la méthode des quotas utilisés par les sondeurs : l’enquête emploi de l’Insee, à partir de laquelle ils redressent leurs échantillons pour les rendre représentatifs, n’inclut pas les territoires d’outre-mer (TOM).
Une explication pourtant insuffisante. Depuis 2014, les départements d’outre-mer (DOM), à l’exception de Mayotte, ont intégré cette enquête. Interrogé sur le sujet, Kantar Public explique que si le nombre d’inscrits est important, la forte abstention dans les DOM-TOM explique leur faible poids sur le résultat final. Mis à part en Réunion (27,14 %), le taux d’abstention s’élevait effectivement autour de 50 % dans les DOM-TOM lors de l’élection présidentielle de 2012.
Une absence de mesure qui pourrait être à l’origine de surprises au soir des résultats, à l’heure où quatre candidats se disputent l’accès au second tour. Au 21 avril 2002, seules 194 600 voix séparaient Lionel Jospin de Jean-Marie Le Pen. Si l’outre-mer a jusqu’à présent relativement moins voté pour le Front national que la France métropolitaine, le soutien de l’ancien président de la Polynésie française autonome, Gaston Flosse, à Marine Le Pen pourrait apporter plusieurs dizaines de milliers de voix à la candidate.
En Polynésie française, les électeurs suivent traditionnellement les consignes de vote des principaux chefs de partis locaux. En 2012, Gaston Flosse avait accordé son soutien à Nicolas Sarkozy, qui avait recueilli plus de 45 % des voix dès le premier tour (contre 27,18 % dans toute la France).